двойной внутренний критик чатбота
Written By: Anna Liednikova
Чтобы с нуля обучить чатбота хорошего качества, как правило, нужно либо много данных, либо очень ограниченный контекст. Ведь его разработчики заинтересованны в успешном выполнении задач чатботом, но редко заинтересованы в детальном описании контекста, где все возможные ситуации будут рассмотрены и предусмотрены. Более эффективным является разработка такого чатбота, который потихоньку и сам разберется в предложенном контексте.
За большинством интересных чатботов скрывается алгоритмы подкрепления (Reinforcement learning), которые имеют свое начало в поведенческой биологии. Очень грубо и просто их можно свести к следующему: есть краткосрочные вознаграждения, а есть долгосрочные, а модель учится определять стратегии, которые балансируют между этими вознаграждениями. Такая своего рода дрессировка на долгосрочную цель.
Говорить на эту тему можно много и долго, но сегодня я бы хотела остановиться только на одной концепции: Исполнитель-Критик (Actor-Critic).
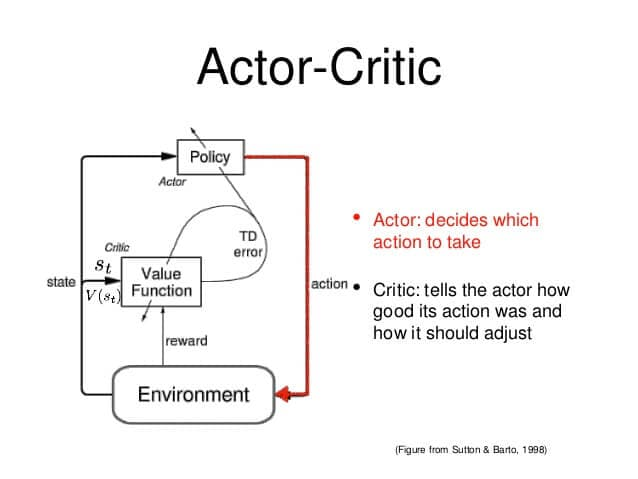
Суть в том, чтобы разделить модель на две части: одну для вычисления действий на основе состояния, а другую - для получения значений результативности этого действия. Как пример, отношения мальчик-мама из этой замечательной статьи:
Ребенок (исполнитель) постоянно пробует новое и исследует окружающую его среду. Он ест свои игрушки, прикасается к раскаленной духовке, бьется головой об стену (почему бы и нет?). Его мать (критик) наблюдает за ним и либо критикует, либо делает комплименты. Ребенок слушает, что ему говорит мать, и корректирует свое поведение. По мере того, как ребенок растет, он узнает, какие действия являются плохими или хорошими, и, по сути, учится играть в игру, называемую жизнью.
Исполнитель принимает на вход состояние и выводит наилучшее действие. По сути, он контролирует поведение агента, изучая оптимальную политику. Критик, с другой стороны, оценивает действие, вычисляя функцию ценности (на основе существующей системе ценностей). Эти две модели участвуют в игре, где со временем они обе становятся лучше в своей роли. В результате общая архитектура научится играть в игру более эффективно, чем два метода по отдельности.
Мотивацией к написанию данного поста послужила новая статья Actor-Double-Critic: Incorporating Model-Based Critic for Task-Oriented Dialogue Systems. В ней авторы показали, что для улучшения диалога, нужно использовать не одного критика, а целых двоих! Один выдвигает свое суждение относительно своих знаний о системе (model-based), а другой - на основе окружения и перспектив (model-free). Такой вот взгляд из прошлого и взгляд из будущего.
Создание такой модели помогло им увеличить успешность чатбота по заказыванию столика в ресторане до 80%. В конце статьи находится пример диалога до и после, с которым я предлагаю вам ознакомится.
А вы как часто взвешиваете решения со своим внутренним критиком? На основе какой информации делаете выводы о результативности ваших действий? На основе существующего опыта? Или желаемых перспектив? Насколько независимы эти суждения?
All Articles
Last updated 2020-11-22 20:01:21 -0400