double critic of chatbot
Written By: Anna Liednikova
To train a good quality chatbot from scratch usually requires either a lot of data or a very limited context. After all, its developers are interested in the successful completion of tasks by the chatbot, but are rarely interested in a detailed description of the context, where all possible situations will be considered and provided for. It is more efficient to develop a chatbot that will slowly figure it out in the proposed context.
Behind most of the interesting chatbots are Reinforcement learning algorithms that have their origins in behavioral biology. Very roughly and simply, they can be summarized as follows: there are short-term rewards, and there are long-term ones, and the model learns to identify strategies that balance between these rewards. This kind of training for a long-term goal.
You can talk a lot and for a long time on this topic, but today I would like to dwell on only one concept: Actor-Critic.
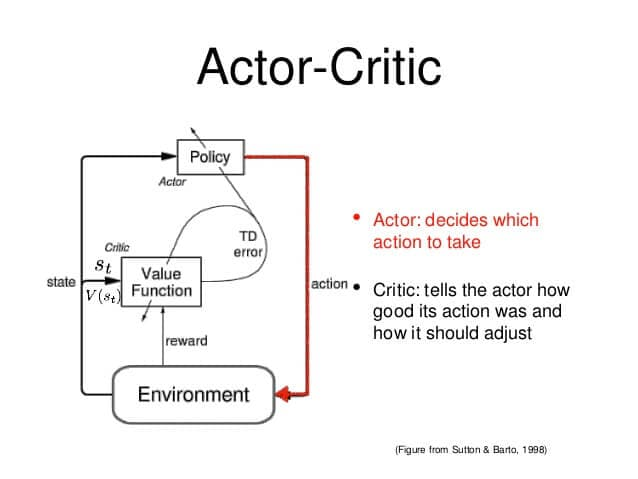
The point is to split the model into two parts: one to calculate the actions based on the state, and the other to get the values of the effectiveness of that action. As an example, the boy-mom relationship from this great article:
The child (actor) constantly tries new things and exploring the environment around him. He eats its own toys, he touches the hot oven, he bangs his head in the wall (I mean why not). His mother (the critic) watches him and either criticize or compliment him. The child listen to what his mother told him and adjust his behavior. As the kid grows, he learns what actions are bad or good and he essentially learns to play the game called life.
The executor takes the state as input and outputs the best action. In essence, he controls the behavior of the agent by studying the optimal policy. The critic, on the other hand, evaluates action by calculating a value function (based on the existing value system). These two models participate in a game where over time they both get better in their role. As a result, the overall architecture will learn to play the game more efficiently than the two methods alone.
The motivation for writing this post was the new article Actor-Double-Critic: Incorporating Model-Based Critic for Task-Oriented Dialogue Systems. In it, the authors showed that to improve the dialogue, you need to use not one critic, but two! One makes his judgment about his knowledge of the system (model-based), and the other - based on the environment and perspectives (model-free). Such is the view from the past and the view from the future.
The creation of such a model helped them increase the success of the chatbot for reserving a table in a restaurant up to 80%. At the end of the article there is an example of a dialogue before and after, which I invite you to familiarize yourself with.
How often do you weigh decisions with your inner critic? On the basis of what information do you draw conclusions about the effectiveness of your actions? Based on existing experience? Or desired perspectives? How independent are these judgments?
All Articles
Last updated 2020-11-22 20:01:21 -0400